







2024年03月26日
3月23日 おもちゃの修理
3月23日
おもちゃ病院の日でしたので修理に行ってきました。
たくさんのおもちゃの修理依頼がありました。
いつものように受付と初期診断で大忙しでした。
私が家に持ち帰ったのはラジコンカーです。
プロポは2.4GHzタイプです。

前進・後退のスティックが前後方向に動かなくなったということで持ち込まれたも
のです。
プロポには、前進・後退と左折・右折の2本のスティックがあります。
左右方向はスティックを動かすと前輪が左右に角度を変えますので問題はありま
せん。
前後方向にはスティックが動きにくいので何かが挟まっているように思えます。
プロポを分解してみました。
アンテナ部分の部品が外れ、スティックが前進方向へ動くのを塞いでしまったよう
です。
タクタイルスイッチをON-OFFするための爪が折れてしまったようです。

詳細に見てみますと見事に爪が折れていました。

根本から完全に折れてしまっていましたので、折れた箇所を加熱し一部溶かして
仮接着し、周囲を2剤セメダインで接着・保護しました。この接着剤は人間が乗る
ボートも修理できる優れものです。

爪の位置、高さはほぼパーフェクトに元通りになりました。

これで修理完了です。
おもちゃ病院の日でしたので修理に行ってきました。
たくさんのおもちゃの修理依頼がありました。
いつものように受付と初期診断で大忙しでした。
私が家に持ち帰ったのはラジコンカーです。
プロポは2.4GHzタイプです。

前進・後退のスティックが前後方向に動かなくなったということで持ち込まれたも
のです。
プロポには、前進・後退と左折・右折の2本のスティックがあります。
左右方向はスティックを動かすと前輪が左右に角度を変えますので問題はありま
せん。
前後方向にはスティックが動きにくいので何かが挟まっているように思えます。
プロポを分解してみました。
アンテナ部分の部品が外れ、スティックが前進方向へ動くのを塞いでしまったよう
です。
タクタイルスイッチをON-OFFするための爪が折れてしまったようです。

詳細に見てみますと見事に爪が折れていました。

根本から完全に折れてしまっていましたので、折れた箇所を加熱し一部溶かして
仮接着し、周囲を2剤セメダインで接着・保護しました。この接着剤は人間が乗る
ボートも修理できる優れものです。

爪の位置、高さはほぼパーフェクトに元通りになりました。

これで修理完了です。
2024年03月19日
3月19日 パソコンでプログラミング
MIFES

これまで数値計算のために各種プログラミング言語でプログラムを書いてきました。
数値計算は、私の場合は、主として微積分方程式体系や動学方程式体系の数値
解を計算したり、方程式体系の不動点(fixed point)を数値で求めることことを指し
ます。
1.そのために、まず解きたい問題を方程式体系等でモデル化します。
これは紙の上に鉛筆で方程式を書くような作業が主です。
2.次に、使いたい数値計算ソフトウェアの文法に即して、モデルを式で書き、解を求
める手順もプログラムにします。
3.次に、MATLABなどのソフトウェアでプログラムを読み取り、変数に値を代入する
など,プログラムが解を計算できる状態にし、実行させます。
まずは、ソフトウェアがエラーを出さずに最後までプログラムが走るか見ます。
エラーが出たらデバッグです。
また、最後まで走り、一応もっともそうな答えを出すからといっても、正しい解を与え
るという保証はありません。
例えば、解法のプログラミングがまずく、解への収束が悪いのだが、変数の初期値
をたまたま一つの解の近傍に設定したのでその解に収束したのかもしれません。
4.あれやこれやプログラムのデバッグと修正を続け研究に必要な結果が出るという
意味で実用程度になるまで精緻化していきます。
私の場合は、数値分析しながら研究を進める事が目的ですのでプログラミング自体
は手段であって目的ではありません。
先述の「各種プログラミング言語でプログラムを書いてきました」というのは主に2と
3です。
プログラム自体はアルファベットや数字、記号からなる単なる文字列です。
文字列からなる命令を読み取り、指示通りに計算処理をするのが、数値計算に関し
てはGAUSS、MATLAB、MATHEMATICAといったソフトウェアです。
このうちGAUSSはそれほど高価ではありません。
しかし、MATLAB、MATHEMATICAは各種のライブラリやソルバーといったものを含
む、フル装備となると使用料が非常に高額です。通常は大学や研究機関で使用する
ことになるといえましょう。
しかし研究者は自宅でも研究を続けたいので、自宅でサービスを受けられないのは
残念です。
そこで、そういう研究者には幸いなことに、自宅バージョンも用意されているのです。

厳密な監理の下で許可されるのですが、長らく恩恵にを受けてきました。
C(C++)は各種OSやソフトウェアを作るための汎用ソフトウェアといえます。
実行ファイル(ソフトウェア、アプリ)を作成するには、コンパイラにかけないといけ
ません。
プログラムを書くためのソフトウェア
ところで、プログラムを書くのに、私は長年MIFESというソフトウェアを使ってきました。
MIFESは、WORDと違って、いわゆるTEXTファイルの作成にほとんど特化したソフ
トウェアです。
特長
1. スクロールスピードが極めて高速。
複数行の文字列、データを丸ごと超スピーディにコピー&ペーストできます。
例えば、プログラムの一部分(40桁300行とか500行丸ごととか)をコピーし、
それを別のWindowに表示させている別のプログラムのある個所に素早く
ペーストすることができます。
C言語では、一つの処理が関数型のまとまりからなっています。
その処理が300行で書かれているなら、それを別のプログラムで使うときは、
その300行を丸ごとコピー&ペーストすれば良いので作業効率が上がります。
2. 16進数で文字を処理できますし、機械語でプログラムを書くこともできます。
3. MIFESからCなどのコンパイラーを走らせる事ができます。
4. コピー&ペーストの速度は鉛筆で紙にメモするのを遙かに凌ぎます。
ばらばらのデータでもMIFESにテキストデータとして記録しておけば、後から
それらをまとめて推敲すれば、文献目録や、講義原稿等の素稿できてしまい
ます。
WORDやPOWERPOINTにペーストし、フォントを変えたりすることも容易です。
数値計算するためのソフトウェア
まずはGAUSSです。

数値計算用のソフトウェアです。
最近はR,Pythonといった無料(Free)ソフトウェアがが使えますが、私はそれらの前
からGAUSSを使ってきました。
現在、家では、GAUSS Light Ver12 (Free Version)を使っています。
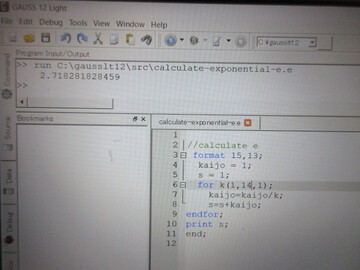
上の画面では、GAUSSの文法に沿って自然対数の底(e)を求める数値計算プログラム
を書き、その値を求めています。
階乗(!)を利用しています。kの階乗とは 1*2*3*・・・・・*k です。
また、eはe=Σ1/k! (k=0,1,2,3,・・・・・・∞)で与えられます。
なお、0!=1です。
画面では、kは1から14までとしています。
format 文で桁数等を指定します。画面では、計算結果が
e=2.718281828459
と表示されています。
小数点以下12桁まで正しい値が得られています。
さらに最近ではFree SoftwearのJuliaがあります。
以下は、私のパソコンにインストールしたJuliaを起動させた写真です。

画面ではJulia で3行3列の対称行列A
6 8 4
7 5 7
4 8 6
の逆行列を計算させるプログラムを示しています。
A=[6 8 4; 7 5 7; 4 8 6]
とすれば上のような3行3列の対称行列を作成できます、
print(inv(A))
とすると、行列Aの逆行列(inverse matrix of A)が画面にプリント(print)されます。
Juliaはマサチューセッツ工科大学(MIT)の研究者を中心にして開発されたソフト
ウェアです。Freeで使えます。Microsoft Visual Studio Codeの下で走らせること
できます。
MIFESでプログラムし、VSCodeで読み取り、デバッグして走らせることができま
す。
GAUSSは行列の操作に少し弱みがあります。
最近のハイスペックでかつFreeのものといえばJuliaかもしれません。
R、Python、JuliaなどFreeWareのなかから自分の使用目的に合い、使い勝手の良
いものを選ぶとよいでしょう。
プログラム言語の間の文法の違いに注意が必要です。
GAUSS の場合
for k(1, 14, 1); という文が写真に写っています。その意味は以下の通りです。
k(1, 14, 1) --------->、kが1から14まで、1ずつ増加する
for-------> 各々のkの値に対してと言う意味。for文の最後にセミコロンを付ける。
Cの場合
for (k = 1 ; k <= 14 ; k++){...........}
上と同じ指示。kは括弧の中に入る。セミコロンで区切る。
上のように、プログラミングでは、コンマ、セミコロン、半角スペースのあるなし一つで、
文法違反になりますので要注意です。
半角空白、全角空白などはディスレイ上では単なる空白ですので意味を持たないよう
に見えますが、PC内ではすべてが数値を持っています。16進数を使うと、半角空白
は0x20、全角空白はShiftJISでは0x8140ですからあくまで数値です。
半角空白2個と全角空白1個は、画面上では幅は同じに見えるとしても、0x20が2個
と0x8140が1個ですから、PCの内部では全く違うものなのです。

これまで数値計算のために各種プログラミング言語でプログラムを書いてきました。
数値計算は、私の場合は、主として微積分方程式体系や動学方程式体系の数値
解を計算したり、方程式体系の不動点(fixed point)を数値で求めることことを指し
ます。
1.そのために、まず解きたい問題を方程式体系等でモデル化します。
これは紙の上に鉛筆で方程式を書くような作業が主です。
2.次に、使いたい数値計算ソフトウェアの文法に即して、モデルを式で書き、解を求
める手順もプログラムにします。
3.次に、MATLABなどのソフトウェアでプログラムを読み取り、変数に値を代入する
など,プログラムが解を計算できる状態にし、実行させます。
まずは、ソフトウェアがエラーを出さずに最後までプログラムが走るか見ます。
エラーが出たらデバッグです。
また、最後まで走り、一応もっともそうな答えを出すからといっても、正しい解を与え
るという保証はありません。
例えば、解法のプログラミングがまずく、解への収束が悪いのだが、変数の初期値
をたまたま一つの解の近傍に設定したのでその解に収束したのかもしれません。
4.あれやこれやプログラムのデバッグと修正を続け研究に必要な結果が出るという
意味で実用程度になるまで精緻化していきます。
私の場合は、数値分析しながら研究を進める事が目的ですのでプログラミング自体
は手段であって目的ではありません。
先述の「各種プログラミング言語でプログラムを書いてきました」というのは主に2と
3です。
プログラム自体はアルファベットや数字、記号からなる単なる文字列です。
文字列からなる命令を読み取り、指示通りに計算処理をするのが、数値計算に関し
てはGAUSS、MATLAB、MATHEMATICAといったソフトウェアです。
このうちGAUSSはそれほど高価ではありません。
しかし、MATLAB、MATHEMATICAは各種のライブラリやソルバーといったものを含
む、フル装備となると使用料が非常に高額です。通常は大学や研究機関で使用する
ことになるといえましょう。
しかし研究者は自宅でも研究を続けたいので、自宅でサービスを受けられないのは
残念です。
そこで、そういう研究者には幸いなことに、自宅バージョンも用意されているのです。

厳密な監理の下で許可されるのですが、長らく恩恵にを受けてきました。
C(C++)は各種OSやソフトウェアを作るための汎用ソフトウェアといえます。
実行ファイル(ソフトウェア、アプリ)を作成するには、コンパイラにかけないといけ
ません。
プログラムを書くためのソフトウェア
ところで、プログラムを書くのに、私は長年MIFESというソフトウェアを使ってきました。
MIFESは、WORDと違って、いわゆるTEXTファイルの作成にほとんど特化したソフ
トウェアです。
特長
1. スクロールスピードが極めて高速。
複数行の文字列、データを丸ごと超スピーディにコピー&ペーストできます。
例えば、プログラムの一部分(40桁300行とか500行丸ごととか)をコピーし、
それを別のWindowに表示させている別のプログラムのある個所に素早く
ペーストすることができます。
C言語では、一つの処理が関数型のまとまりからなっています。
その処理が300行で書かれているなら、それを別のプログラムで使うときは、
その300行を丸ごとコピー&ペーストすれば良いので作業効率が上がります。
2. 16進数で文字を処理できますし、機械語でプログラムを書くこともできます。
3. MIFESからCなどのコンパイラーを走らせる事ができます。
4. コピー&ペーストの速度は鉛筆で紙にメモするのを遙かに凌ぎます。
ばらばらのデータでもMIFESにテキストデータとして記録しておけば、後から
それらをまとめて推敲すれば、文献目録や、講義原稿等の素稿できてしまい
ます。
WORDやPOWERPOINTにペーストし、フォントを変えたりすることも容易です。
数値計算するためのソフトウェア
まずはGAUSSです。

数値計算用のソフトウェアです。
最近はR,Pythonといった無料(Free)ソフトウェアがが使えますが、私はそれらの前
からGAUSSを使ってきました。
現在、家では、GAUSS Light Ver12 (Free Version)を使っています。

上の画面では、GAUSSの文法に沿って自然対数の底(e)を求める数値計算プログラム
を書き、その値を求めています。
階乗(!)を利用しています。kの階乗とは 1*2*3*・・・・・*k です。
また、eはe=Σ1/k! (k=0,1,2,3,・・・・・・∞)で与えられます。
なお、0!=1です。
画面では、kは1から14までとしています。
format 文で桁数等を指定します。画面では、計算結果が
e=2.718281828459
と表示されています。
小数点以下12桁まで正しい値が得られています。
さらに最近ではFree SoftwearのJuliaがあります。
以下は、私のパソコンにインストールしたJuliaを起動させた写真です。

画面ではJulia で3行3列の対称行列A
6 8 4
7 5 7
4 8 6
の逆行列を計算させるプログラムを示しています。
A=[6 8 4; 7 5 7; 4 8 6]
とすれば上のような3行3列の対称行列を作成できます、
print(inv(A))
とすると、行列Aの逆行列(inverse matrix of A)が画面にプリント(print)されます。
Juliaはマサチューセッツ工科大学(MIT)の研究者を中心にして開発されたソフト
ウェアです。Freeで使えます。Microsoft Visual Studio Codeの下で走らせること
できます。
MIFESでプログラムし、VSCodeで読み取り、デバッグして走らせることができま
す。
GAUSSは行列の操作に少し弱みがあります。
最近のハイスペックでかつFreeのものといえばJuliaかもしれません。
R、Python、JuliaなどFreeWareのなかから自分の使用目的に合い、使い勝手の良
いものを選ぶとよいでしょう。
プログラム言語の間の文法の違いに注意が必要です。
GAUSS の場合
for k(1, 14, 1); という文が写真に写っています。その意味は以下の通りです。
k(1, 14, 1) --------->、kが1から14まで、1ずつ増加する
for-------> 各々のkの値に対してと言う意味。for文の最後にセミコロンを付ける。
Cの場合
for (k = 1 ; k <= 14 ; k++){...........}
上と同じ指示。kは括弧の中に入る。セミコロンで区切る。
上のように、プログラミングでは、コンマ、セミコロン、半角スペースのあるなし一つで、
文法違反になりますので要注意です。
半角空白、全角空白などはディスレイ上では単なる空白ですので意味を持たないよう
に見えますが、PC内ではすべてが数値を持っています。16進数を使うと、半角空白
は0x20、全角空白はShiftJISでは0x8140ですからあくまで数値です。
半角空白2個と全角空白1個は、画面上では幅は同じに見えるとしても、0x20が2個
と0x8140が1個ですから、PCの内部では全く違うものなのです。
2024年03月17日
3月12日 C言語
Q:C言語ではエスケープ文字としてバックスラッシュを使いますが、
日本語では円記号を使うのは何故ですか。
A:これは、バックスラッシュのASCIIコードが 16進数の5C(0x5c、5Ch)
であることと、日本語のJISコードにおいては円記号がASCIIコードの 5Ch
に割り当てられていることによります。
つまり、コードが一致しているからです。
Q:C言語では文字も数字も一緒くたに扱われているように思えます。
初心者には紛らわしいのですが。
A:
私たちが画面で見る文字も数字も、最小情報量であるビット(0 か 1)
の組み合わせで表現されます。
例えば、ASCIIコードでは、英字の A は41h(0x41)という値で表現されます。
最も機械に近いレベルで表現すると 01000001 です。
つまり、'A'も0x41も機械内部では 01000001 であり、画面上では 英字のAです。
したがって、C言語では、変数をXとして、X='A'とするのと、X=0x41
とするのは同じことになります。
紛らわしく感じるのは、画面上の数字や文字をそのまま受け取るからです。
次のように考えると良いでしょう。私たちは文字「A」を文字そのものとして
理解していますが、コンピュータが扱う最小情報量はビットで 0 か 1ですから、
「A」そのものは認識できません。そこで、「A」を 01000001 に当てはめ、機
械で「A」という文字を処理できるようにしているのです。ただし、0 と1の並
びは人間にわかりにくいので、通常は16進数で表現されます。Aは 01000001
ですから、16進数で41となります。
コンピュータでの表現 画面での英数字
------------------------------------------------------------
16進数の 48 65 6C 6C 6F 英字で H e l l o
16進数の 31 32 33 34 35 数字の 1 2 3 4 5
とにかく、私たちが使う文字や数字が機械の内部ではどのように扱われているか、
ということに興味を持つことです。
Q:よく「文字化けする」ということを耳にしますが、文字化けする原理を教えて下さい。
A:まず、C言語との関連で説明しましょう。例えば、エスケープ文字は円記号(¥)で、
そのASCIIコードは 5Chです。ここで、漢字の「表」を例に取ると、シフトJISでは16進数
の 955C です。もうお分かりですね。もしコンパイラなどが 955C を漢字と認識せず、95と5C
と別々に読むと、5Ch は '\' ですから文字として認識されません。したがって、955Ch は 95
だけとして読まれてしまい、「表」はどこかへ消えます。古いコンパイラ(Lattice C ver.2
など)ではよくあった話です。現在のCコンパイラは漢字を扱えますが、注意はしておく必要
があります。
次に、漢字コードの関係で文字化けが生じる原因を説明しましょう。漢字変換には、パソコン
ではJISコードやシフトJISコード、ワークステーションではEUCコードが使われます。
例えば、「大学」を例にとると、
大 学
シフトJISでは、91E5 8A77
JISでは、4267 3358
と16進数の値が異なります。このように、同一漢字でも16進数が異なることから、漢字を認識
する方法も異なるということになります。ですから、異なる機種の間で通信する場合はコード
を自動的に判別するソフトでないと文字化けすることがあります。自分のパソコンがどの漢字
コードを用いているか、通信の相手がどのコードを用いているかを調べておくことも重要です。
試しに、図書館を呼び出して、図書検索をEUCコードと異なるコートでやってみて下さい。
Q:通信ではファイルをバイナリで送ったり(アップロード)、受け取ったり(ダウンロード)
するのが安全といわれますが何故ですか。
A: Internet の Q&A に書いて有ります。そこをご覧下さい。
Q:マスクとはどのようなことですか。
A:例で示しましょう。
X & 0X00FF とは、数字X と 0X00FFとのビットごとのANDをとることです。
0X00FFをビットで示す(上段はビット、下段はビットフィールド)と、
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
----------------------------------------------------------
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
となります。上位8ビットはゼロですから、Xと0X00FFとのANDをとった数も、
上位8ビットはゼロになります。つまり、上位8ビットはフィルターをかけ
て隠すことを意味しますので、マスクするというわけです。
その他の例
X & 0x7fff 15ビット目をマスク
X & 0x003f 6ビット目以上をマスク
X & 0x000f 4ビット目以上をマスク
(補足)
インターネットでは「サブネットマスク」が使われます。
サブネットマスクは十進数のオクテットで、
255.255.0.0
255.255.255.0
などと表されます。
10進数の255は、16進数の FF、2進数の 11111111 です。
10進数の 0 は、16進数の 00、2進数の 00000000 です。
これから、なぜ「マスク」というのか予想できますね。
「サブネットマスク」については、Internetのページに説明があ
ります。
Q:ビットシフトとはどのようなことですか。
A:例で示しましょう。
0XFF00 >> 8 の場合、右へ8ビットシフトすると、右側の8ビットは除か
れ、代わりに左側に8ビット分 0が詰められます。
図示しますと、
1111 1111 0000 0000 ・・・・ 0XFF00
-----------------------------
1111 1111 ・・・・ 右の8ビット( 0000 0000)が除かれる
0000 0000 ・・・・ 左に8ビット0が詰められる
-----------------------------
0000 0000 1111 1111 ・・・・ 結局、0X00FF となる。
Q:マスクやビットシフトはどのようなことに応用されますか。
A:例で示しましょう。
例題:構造体の中に「年月日」を示す16ビットのビットフィールド
が入っているものとします。
Borland C++ Ver3.0 の ffblk.ff_fdate を例にとっています。
ffblk.ff_fdate のビットフィールド・・・ 日:ビット 0-4
月:ビット 5-8
年:ビット 9-15
図示すると、
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
|------- 年 --------------|---- 月 -----|---- 日 -------|
となります。
ここで、年(1980年以降の年数)をy、月(1-12)をm、日(1-31)をd、としましょう。
年を得るのは簡単ですね。ffblk.ff_fdate を9ビット右へシフトすればよい。
(「月日」の桁を削除し、残った「年」を右へ桁下げすると考えると分かり易い)
結局
y = ffblk.ff_fdate >> 9;
日を得るのはどうですか。ffblk.ff_fdate の 左側11ビットをマスクすればよい。
0000 0000 0001 1111 は 0X001F です。
結局、
d = ffblk.ff_fdate & 0X001F;
月を得るのは少々手強いです。月を得るのは、マスクとビットシフトの応用問題です。
まず、5ビット右へシフトさせて、日の5ビットを捨てましょう。
すると 00000年月 が イメージとしてのビットフィールドになります。
次に、月(下位4ビット)だけ残すために、上位12ビットをマスクして隠します。
マスクするのは上位12ビットですから、
0000 0000 0000 1111 との AND をとればよい。( 0X000F との AND をとる。)
結局、
m = ( ffblk.ff_fdate >> 5 ) & 0X000F
分かりましたか。初級者には、ビット操作は無理かもしれません。しかし、C言語の魅
力の一つはこういったビット単位の操作が可能なことにあるのです。
Q:最も簡単なプログラムを一つあげてCのプログラムを説明して下さい。
A:どの入門書でも、"Hello World" と表示するだけのものから始まります。
①最も簡単なプログラムは、以下のような5行のプログラムです。
=====================================================
#include "stdio.h"
void main(void)
{
printf("\n Hello World \n");
}
=====================================================
・Cプログラムは関数の集まりのような形をしています。
・ #include は、プリプロセッサにヘッダファイル(stdio.h)を取り込ませる命令です。
stdio.h は基本的な inputとoutputのきまりを指定したファイルです。
stdio.hの両端を右のようにくくります。<stdio.h> もしくは "stdio.h"
--------------------------------------------------------------------
注意: "<" と ">" は半角です!! ここでは全角になっていますが、こ
うしないと netscape navigator はタグ(tag)と受け取り、画面に表
示されなくなるからです。
--------------------------------------------------------------------
どのプログラムにもstdio.hは必要です。
プリプロセッサ制御命令にはセミコロン(;)はつけません。
main()が必要です。中身は{ と }の間に書きます。
printf()は画面に表示する命令です。表示の中身は "Hello World" です。
"\n" は改行を意味します。
ですから、"\n Hello World \n" は、まず改行し、"Hello World" を表示し、改行する
ことを意味します。文の最後にセミコロン(;)をつけます。
②次は、画面消去後 "Hello World" と表示させます。
=====================================================
#include "stdio.h"
void main(void)
{
printf("\x01b[2J");
printf("Hello World \n");
}
=====================================================
printf("\x01b[2J") は画面消去命令です。\x01b はエスケープコードです。
また、例えば画面を青くしたければ、
printf("\x01b[34m");
とします。これはDOSに対する命令の仕組みですので、こういう場合はこう命令
するのだと覚えるのがC言語上達の近道です。
"Hello World \n" と、"Hello World" の前に \n がないのは、画面を消去したの
で、改行する必要がないからです。
Q:ポインタが分からなくてC言語から落ちこぼれる人が多いと聞きますが。
A:そうらしいですね。
ポインタは変数や関数のアドレスをもつ変数です。
ポインタと配列との関係
pがポインタ変数で、その内容が "HELLO"であるとすると、以下のようになります。
p == "HELLO"
*p == p[0] == "H"
*(p+1) == p[1] == "E"
*(p+2) == p[2] == "L"
*(p+3) == p[3] == "L"
*(p+4) == p[4] == "O"
文字列へのポインタの例を示します。
void string(*st)
{
int i = 0;
int count = 0;
char *str;
str = st; /*文字列の代入(アドレスを一致させる)*/
while( str[i] != '\0' ) {
printf( "str[%d] = %c\n", i, str[i] );
/*1文字ずつプリントする*/
i++;
count++;
}
printf( "Number of Characters = %d \n", count );
/*文字数をプリントする*/
}
日本語では円記号を使うのは何故ですか。
A:これは、バックスラッシュのASCIIコードが 16進数の5C(0x5c、5Ch)
であることと、日本語のJISコードにおいては円記号がASCIIコードの 5Ch
に割り当てられていることによります。
つまり、コードが一致しているからです。
Q:C言語では文字も数字も一緒くたに扱われているように思えます。
初心者には紛らわしいのですが。
A:
私たちが画面で見る文字も数字も、最小情報量であるビット(0 か 1)
の組み合わせで表現されます。
例えば、ASCIIコードでは、英字の A は41h(0x41)という値で表現されます。
最も機械に近いレベルで表現すると 01000001 です。
つまり、'A'も0x41も機械内部では 01000001 であり、画面上では 英字のAです。
したがって、C言語では、変数をXとして、X='A'とするのと、X=0x41
とするのは同じことになります。
紛らわしく感じるのは、画面上の数字や文字をそのまま受け取るからです。
次のように考えると良いでしょう。私たちは文字「A」を文字そのものとして
理解していますが、コンピュータが扱う最小情報量はビットで 0 か 1ですから、
「A」そのものは認識できません。そこで、「A」を 01000001 に当てはめ、機
械で「A」という文字を処理できるようにしているのです。ただし、0 と1の並
びは人間にわかりにくいので、通常は16進数で表現されます。Aは 01000001
ですから、16進数で41となります。
コンピュータでの表現 画面での英数字
------------------------------------------------------------
16進数の 48 65 6C 6C 6F 英字で H e l l o
16進数の 31 32 33 34 35 数字の 1 2 3 4 5
とにかく、私たちが使う文字や数字が機械の内部ではどのように扱われているか、
ということに興味を持つことです。
Q:よく「文字化けする」ということを耳にしますが、文字化けする原理を教えて下さい。
A:まず、C言語との関連で説明しましょう。例えば、エスケープ文字は円記号(¥)で、
そのASCIIコードは 5Chです。ここで、漢字の「表」を例に取ると、シフトJISでは16進数
の 955C です。もうお分かりですね。もしコンパイラなどが 955C を漢字と認識せず、95と5C
と別々に読むと、5Ch は '\' ですから文字として認識されません。したがって、955Ch は 95
だけとして読まれてしまい、「表」はどこかへ消えます。古いコンパイラ(Lattice C ver.2
など)ではよくあった話です。現在のCコンパイラは漢字を扱えますが、注意はしておく必要
があります。
次に、漢字コードの関係で文字化けが生じる原因を説明しましょう。漢字変換には、パソコン
ではJISコードやシフトJISコード、ワークステーションではEUCコードが使われます。
例えば、「大学」を例にとると、
大 学
シフトJISでは、91E5 8A77
JISでは、4267 3358
と16進数の値が異なります。このように、同一漢字でも16進数が異なることから、漢字を認識
する方法も異なるということになります。ですから、異なる機種の間で通信する場合はコード
を自動的に判別するソフトでないと文字化けすることがあります。自分のパソコンがどの漢字
コードを用いているか、通信の相手がどのコードを用いているかを調べておくことも重要です。
試しに、図書館を呼び出して、図書検索をEUCコードと異なるコートでやってみて下さい。
Q:通信ではファイルをバイナリで送ったり(アップロード)、受け取ったり(ダウンロード)
するのが安全といわれますが何故ですか。
A: Internet の Q&A に書いて有ります。そこをご覧下さい。
Q:マスクとはどのようなことですか。
A:例で示しましょう。
X & 0X00FF とは、数字X と 0X00FFとのビットごとのANDをとることです。
0X00FFをビットで示す(上段はビット、下段はビットフィールド)と、
0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1
----------------------------------------------------------
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
となります。上位8ビットはゼロですから、Xと0X00FFとのANDをとった数も、
上位8ビットはゼロになります。つまり、上位8ビットはフィルターをかけ
て隠すことを意味しますので、マスクするというわけです。
その他の例
X & 0x7fff 15ビット目をマスク
X & 0x003f 6ビット目以上をマスク
X & 0x000f 4ビット目以上をマスク
(補足)
インターネットでは「サブネットマスク」が使われます。
サブネットマスクは十進数のオクテットで、
255.255.0.0
255.255.255.0
などと表されます。
10進数の255は、16進数の FF、2進数の 11111111 です。
10進数の 0 は、16進数の 00、2進数の 00000000 です。
これから、なぜ「マスク」というのか予想できますね。
「サブネットマスク」については、Internetのページに説明があ
ります。
Q:ビットシフトとはどのようなことですか。
A:例で示しましょう。
0XFF00 >> 8 の場合、右へ8ビットシフトすると、右側の8ビットは除か
れ、代わりに左側に8ビット分 0が詰められます。
図示しますと、
1111 1111 0000 0000 ・・・・ 0XFF00
-----------------------------
1111 1111 ・・・・ 右の8ビット( 0000 0000)が除かれる
0000 0000 ・・・・ 左に8ビット0が詰められる
-----------------------------
0000 0000 1111 1111 ・・・・ 結局、0X00FF となる。
Q:マスクやビットシフトはどのようなことに応用されますか。
A:例で示しましょう。
例題:構造体の中に「年月日」を示す16ビットのビットフィールド
が入っているものとします。
Borland C++ Ver3.0 の ffblk.ff_fdate を例にとっています。
ffblk.ff_fdate のビットフィールド・・・ 日:ビット 0-4
月:ビット 5-8
年:ビット 9-15
図示すると、
15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
|------- 年 --------------|---- 月 -----|---- 日 -------|
となります。
ここで、年(1980年以降の年数)をy、月(1-12)をm、日(1-31)をd、としましょう。
年を得るのは簡単ですね。ffblk.ff_fdate を9ビット右へシフトすればよい。
(「月日」の桁を削除し、残った「年」を右へ桁下げすると考えると分かり易い)
結局
y = ffblk.ff_fdate >> 9;
日を得るのはどうですか。ffblk.ff_fdate の 左側11ビットをマスクすればよい。
0000 0000 0001 1111 は 0X001F です。
結局、
d = ffblk.ff_fdate & 0X001F;
月を得るのは少々手強いです。月を得るのは、マスクとビットシフトの応用問題です。
まず、5ビット右へシフトさせて、日の5ビットを捨てましょう。
すると 00000年月 が イメージとしてのビットフィールドになります。
次に、月(下位4ビット)だけ残すために、上位12ビットをマスクして隠します。
マスクするのは上位12ビットですから、
0000 0000 0000 1111 との AND をとればよい。( 0X000F との AND をとる。)
結局、
m = ( ffblk.ff_fdate >> 5 ) & 0X000F
分かりましたか。初級者には、ビット操作は無理かもしれません。しかし、C言語の魅
力の一つはこういったビット単位の操作が可能なことにあるのです。
Q:最も簡単なプログラムを一つあげてCのプログラムを説明して下さい。
A:どの入門書でも、"Hello World" と表示するだけのものから始まります。
①最も簡単なプログラムは、以下のような5行のプログラムです。
=====================================================
#include "stdio.h"
void main(void)
{
printf("\n Hello World \n");
}
=====================================================
・Cプログラムは関数の集まりのような形をしています。
・ #include は、プリプロセッサにヘッダファイル(stdio.h)を取り込ませる命令です。
stdio.h は基本的な inputとoutputのきまりを指定したファイルです。
stdio.hの両端を右のようにくくります。<stdio.h> もしくは "stdio.h"
--------------------------------------------------------------------
注意: "<" と ">" は半角です!! ここでは全角になっていますが、こ
うしないと netscape navigator はタグ(tag)と受け取り、画面に表
示されなくなるからです。
--------------------------------------------------------------------
どのプログラムにもstdio.hは必要です。
プリプロセッサ制御命令にはセミコロン(;)はつけません。
main()が必要です。中身は{ と }の間に書きます。
printf()は画面に表示する命令です。表示の中身は "Hello World" です。
"\n" は改行を意味します。
ですから、"\n Hello World \n" は、まず改行し、"Hello World" を表示し、改行する
ことを意味します。文の最後にセミコロン(;)をつけます。
②次は、画面消去後 "Hello World" と表示させます。
=====================================================
#include "stdio.h"
void main(void)
{
printf("\x01b[2J");
printf("Hello World \n");
}
=====================================================
printf("\x01b[2J") は画面消去命令です。\x01b はエスケープコードです。
また、例えば画面を青くしたければ、
printf("\x01b[34m");
とします。これはDOSに対する命令の仕組みですので、こういう場合はこう命令
するのだと覚えるのがC言語上達の近道です。
"Hello World \n" と、"Hello World" の前に \n がないのは、画面を消去したの
で、改行する必要がないからです。
Q:ポインタが分からなくてC言語から落ちこぼれる人が多いと聞きますが。
A:そうらしいですね。
ポインタは変数や関数のアドレスをもつ変数です。
ポインタと配列との関係
pがポインタ変数で、その内容が "HELLO"であるとすると、以下のようになります。
p == "HELLO"
*p == p[0] == "H"
*(p+1) == p[1] == "E"
*(p+2) == p[2] == "L"
*(p+3) == p[3] == "L"
*(p+4) == p[4] == "O"
文字列へのポインタの例を示します。
void string(*st)
{
int i = 0;
int count = 0;
char *str;
str = st; /*文字列の代入(アドレスを一致させる)*/
while( str[i] != '\0' ) {
printf( "str[%d] = %c\n", i, str[i] );
/*1文字ずつプリントする*/
i++;
count++;
}
printf( "Number of Characters = %d \n", count );
/*文字数をプリントする*/
}
2024年03月03日
2月25日 おもちゃの修理
2月25日
おもちゃの修理をしました。
TOMICA SPIRAL ELEVATOR
トミカの螺旋エレバーター


電源をONにしてもエレベーターが回転しないということで修理依頼の
あったおもちゃです。
まずは電池Boxの点検です。
端子やフューズに問題はなく、単2の電池2本分の端子間電圧はしっか
り出ます。
そこで、底蓋を外して内部を点検します。


問題のありそうな部品はスライドスイッチです。
点検の結果、ON-OFF(導通ー導通なし)に問題がありそうです。
そこで、プラス端子は導線を少し切り詰めてハンダを付け直す、マイナス
端子はもう一方の使用していなかった端子を使用する、最後に、スライド
スイッチは、これまでとは左右逆にして本体に取り付けれる、ということに
しました。

これで、スイッチの機能が元通りになりました。

最後に、エレバーター駆動システム部分の点検です。

ギアシステムにの点検では問題ありません。
次にモーターですが、電圧を印加するとしっかり回転します。
トルクも十分あります。
そこで、モーターとスライドスイッチ間のリード線を交換することにしました。
これで、問題のありそうな箇所の点検・修理は終了です。
底蓋を組み立て、車を使ってエレベーターが正常に稼働するか点検します。
坂道を下ってきた車はエレベータ前のストッパーで止まる、
ストッパーが外れる、
車はエレベーター内に移動する、
車は螺旋エレベータの回転とともに上昇する、
車は出口からエレベータの外に出る。
エレベーターは一連の機能をしっかり果たすようになりました。
修理完了です。
おもちゃの修理をしました。
TOMICA SPIRAL ELEVATOR
トミカの螺旋エレバーター


電源をONにしてもエレベーターが回転しないということで修理依頼の
あったおもちゃです。
まずは電池Boxの点検です。
端子やフューズに問題はなく、単2の電池2本分の端子間電圧はしっか
り出ます。
そこで、底蓋を外して内部を点検します。


問題のありそうな部品はスライドスイッチです。
点検の結果、ON-OFF(導通ー導通なし)に問題がありそうです。
そこで、プラス端子は導線を少し切り詰めてハンダを付け直す、マイナス
端子はもう一方の使用していなかった端子を使用する、最後に、スライド
スイッチは、これまでとは左右逆にして本体に取り付けれる、ということに
しました。

これで、スイッチの機能が元通りになりました。

最後に、エレバーター駆動システム部分の点検です。

ギアシステムにの点検では問題ありません。
次にモーターですが、電圧を印加するとしっかり回転します。
トルクも十分あります。
そこで、モーターとスライドスイッチ間のリード線を交換することにしました。
これで、問題のありそうな箇所の点検・修理は終了です。
底蓋を組み立て、車を使ってエレベーターが正常に稼働するか点検します。
坂道を下ってきた車はエレベータ前のストッパーで止まる、
ストッパーが外れる、
車はエレベーター内に移動する、
車は螺旋エレベータの回転とともに上昇する、
車は出口からエレベータの外に出る。
エレベーターは一連の機能をしっかり果たすようになりました。
修理完了です。
2024年03月02日
2月18日 おもちゃの修理
2月18日
おもちゃの修理
家に持ち帰ったのはFJクルーザー


水上でも走る高級ラジコンです。
プロポの状態がよくないので、本体を制御して走らせるように修理することはできませんでした。
おもちゃの修理
家に持ち帰ったのはFJクルーザー


水上でも走る高級ラジコンです。
プロポの状態がよくないので、本体を制御して走らせるように修理することはできませんでした。
2024年03月02日
2月11日 アマチュア無線機 FTDX101MP firmware update
2月11日
アマチュア無線機 FTDX101MP firmware update
アマチュア無線機の firmwareをupdateしました。


たまにアップデートとかしてメインテナンスしておく必要があります「。
アマチュア無線機 FTDX101MP firmware update
アマチュア無線機の firmwareをupdateしました。


たまにアップデートとかしてメインテナンスしておく必要があります「。









